Here at Jodoro we’ve been working on the release of a Collaborative Modeling Tool designed to run out of a browser using Adobe Flex [1]. The basic premise of the application is to allow users to develop, customize, extend, or just make use of industry standards and shared models.
It's conceivable that the data sets (the models) being accessed by the client could get quite large. So we decided on an online, delta-driven communications approach. The Flex application maintains a local cache in memory for each session, retrieving data on demand when it cannot be found in the local cache.
As we started to design the user interface and discuss the sorts of features that users would expect, we naturally raised the topic of whether the user should be able to undo their work. Even though it seems to be often overlooked, we decided that Undo/Redo was important for the overall usability.
Our first thought was that there was a natural fit between the Undo/Redo actions and the delta-based communications. As such I was expecting the Undo/Redo features would be relatively straightforward to implement. However, it didn't take long for all the corner cases to emerge, and it turned out to be trickier than I’d first expected. Now that we have a fully functioning framework, I felt it worthy a blog article.
We started by discussing what our users would want and what did and didn’t work well in other applications that we use in our own everyday lives. It's somewhat common that a user can only Undo back to their last save point, or a preset number of steps, but we decided our application should preferably support undoing all the way back to the start of their current session.
One feature not often implemented is actually forking all the different Undo/Redo pathways as the user worked. However, we decided this was much too complex for the user to track, and settled on a linear progression.
We also muted on getting rid of Save entirely – instead synchronizing on every user action, or at some logical interval. Whilst this was technically possible, we decided that keeping the existing Save metaphor would be more comfortable for users. Finally we decided a cancel function to return the user to their last Save Point would also be useful (although not strictly necessary).
Framework
With my requirements in hand I set about designing the framework. I decided to capture a linked list, the Delta Chain, of all of the user actions that change the state of my model. To simplify the implementation I initialize the Delta Chain with a
StartPlaceHolder Delta Object that, as the name suggests, always remains at the front of the chain. The framework keeps a pointer,
currentDelta, to the most recently executed Delta Object, initially pointing to the
StartPlaceHolder Delta Object. This pointer is represented in all of the diagrams below as a red triangle.

Figure 1: Basic action manipulationFigure 1 demonstrates the frame-by-frame changes in the Delta Object chain as various user actions and undo and redo commands are enacted by the user. New Delta Objects are always added to the current end of the chain, and the currentDelta pointer is always updated to point to the newly added delta. As the user undoes their actions the pointer moves to the left, towards the
StartPlaceHolder in the Delta Chain. As they redo the actions the pointer moves to the right. If a user has undone one or more items when a new action is added, the framework drops the undone Delta Obects and attaches the new Delta Object to the right of the currentDelta pointer, then updates the currentDelta to reference the newly added Delta Object. My
StartPlaceHolder token can never be undone, and hence can also never be dropped.
I created an
IModelDelta interface to be realized by all of my Delta Objects, and added the following methods:
function doAction(m:Model):void;
function undoAction(m:Model):void;
function redoAction(m:Model):void; My framework executes the
doAction method when a Delta Object is first added to the Delta Chain (and never again).
undoAction and
redoAction are called for every Undo and Redo of that action respectively.
Save
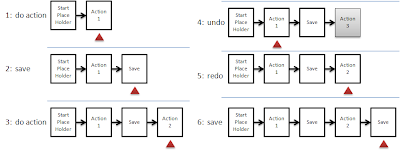 Figure 2: Saving actions
Figure 2: Saving actionsI then moved to the
SaveDelta (
Figure 2), which in our case was an action to send model deltas in XML format to the server, based upon changes since the last save. The actual save itself is treated as a special case and can never be undone –the data has already been persisted to the server. If a user undoes back past a Save Point, the next user enacted save will calculate the necessary deltas (reversals) in order to make the model consistent.
The
SaveDelta doAction generates the combined XML by making use of another
IModelDelta method:
function generateXMLDeltas(m:Model):XMLList;The
SaveDelta doAction method traverses backwards along the chain of Delta Objects and calls
generateXMLDeltas for each Delta Object until it reaches the last stable save point. One of my early realizations was that the last stable save point may not necessarily be a SaveDelta. It may obviously be the
StartPlaceHolder, but it could also be a
CancelDelta, which I discuss later in the article.
As in
Figure 1, if the user performs an Undo, and then another task, the undone Delta Object is discarded. This approach works fine for any deltas that have not yet been saved to the server, but is more difficult when the user has undone past a Save Point – these cannot simply be discarded as we need to generate reversals at the next Save. There are a number of options to handle this:
- The framework could generate the reversals upon discarding the objects, and update the server immediately. This simplifies the Delta Chain, but at the expense of increased server communications and inconsistency with the Save/Cancel metaphor.
- The reversal XML could be generated and stored in memory until the next SaveDelta doAction method is executed. This again simplifies the Delta Chain, but means the Undo/Redo framework needs to also understand the reversal data. The XML generation also becomes disjointed.
- The saved delta objects could be stored in a temporary list until the next SaveDelta doAction is executed. This creates an overhead of moving objects around arrays in memory, and is more complicated to build, but is actually quite a clean approach. It also takes the actions out of order which is fine unless you intend to implement a cancel function.
- The objects could be left in place and marked to indicate to the framework that they are to be ignored except by the next SaveDelta doAction which will generate its reversal XMLs and drop it from the chain.
 Figure 3: Undoing actions already saved
Figure 3: Undoing actions already savedMy current implementation is option 4 (
Figure 3). I introduced a new flag called isDead and added four new methods to our IModelDelta interface:
function isDone():Boolean;
function setDoneFlag(d:Boolean):void;
function isDead():Boolean;
function setDeadFlag(d:Boolean):void;
The framework now determines whether a Delta Object should be discarded, or just marked dead based on whether the Delta Object had already been saved to server. Such Delta Objects are easy to detect as they have been undone and lie to the left of a
SaveDelta in the chain. The framework also now ignores dead objects, skipping them in all Undo and Redo actions (along with all
SaveDeltas). To everything except the next executed
SaveDelta doAction method a dead Delta Object is dead! Finally I revisited my
generateXMLDelta methods for each Delta Object and upgraded them to generate reversal XML deltas when the object is in a dead state.
It is also worth noting that there is a difference between an item that has been undone and lies before the previous
SaveDelta, and a delta that has been marked dead. The first scenario happens when users undo actions that have already been saved, but can still be redone by the user. The second scenario represents items that would have been discarded if not for the fact that they have already been saved to the server – The user can no longer redo these actions, but we still need to generate a reversal.
My
SaveDelta doAction currently iterates backwards through the Delta Object chain looking for:
- Actioned Delta Objects that haven’t yet been saved. When traversing backwards from the current SaveDelta, these deltas always appear before a previous CancelDelta or SaveDelta (or StartPlaceHolder).
- Undone Delta Objects that have been marked dead. Again traversing backwards from the current SaveDelta, these always appear after a previous SaveDelta. Technically the implementation can take advantage of the linear nature of the Delta Chain and only keep looking for dead Delta Objects while the Delta Objects remain dead. My implementation of cancel (details below) complicates this and I’m currently traversing the entire Delta Chain. At some point this will become a performance bottleneck and I will need to revisit to determine more accurately where to stop traversing.
Cancel
The
CancelDelta needs to bring the system back to the last save point. This could be a
SaveDelta, or the
StartPlaceHolder, or it could be another
CancelDelta. This is because the previous
CancelDeltas themselves were resulting in returning the system to the last save point. Unlike Save, I chose to implement
CancelDelta as an action that can be undone and redone. This adds complexity, but we felt also added a justifiable amount of usability.
There are two types of actions that need to be handled for a cancel:
- Any actions that have been executed since the last save need to be undone.
- Any actions that have been marked dead since the last save need to be redone and marked alive. (This scenario only occurs if the user has undone items that were executed before the last save.)
 Figure 4: Cancelling unsaved actions
Figure 4: Cancelling unsaved actionsWhen all of the actions in the scope of the
CancelDelta have occurred since the last stable save point (
Figure 4), the
doAction of the
CancelDelta simply needs to undo these Delta Objects. The
CancelDelta undoAction and
redoAction should then respectively redo and undo these very same Delta Objects.
 Figure 5: Cancelling undoes of saved actions
Figure 5: Cancelling undoes of saved actionsHowever, if Delta Objects before the
SaveDelta have been marked dead (
Figure 5), the
CancelDelta doAction also needs to resurrect them and call their
redoAction methods. The
CancelDelta undoAction also needs to call each Delta Object’s undoAction, and reinstate each as dead. The
CancelDelta redoAction finally needs to reverse the steps again.
 Figure 6: A complex cancel scenario
Figure 6: A complex cancel scenarioThere will also be scenarios where the same
CancelDelta needs to manage both the undoing of actioned but unsaved Delta Objects and the resurrecting of dead Delta Objects (
Figure 6). Luckily because new Delta Objects are always added to the end of the Delta Chain, and any undone items not saved are dropped, the Undone Dead Delta Objects that need to be Redone will always appear in the Delta Chain immediately before the actioned Delta Objects that need to be undone (ignoring SaveDeltas). As such, in my implementation of the
CancelDelta doAction method I keep two counters, (1) the number of unsaved deltas I reverse, and (2) the number of dead deltas I resurrect. My
CancelDelta undoAction and
redoAction methods use these two counters to ensure they unwind and rewind the Deltas in the correct ways and order.
Summary
With all of this in place I was finally ready to start building the real user actions! But you’ll be pleased to know that this became the easy part. I just needed to ensure that each new Delta Object’s
doAction,
undoAction and
redoAction methods left the local cached model in the correct respective states, and that the
generateXMLDeltas method implemented the correct XML deltas and reversals based on the current state of that Delta Object. The framework I’d built handled the rest for me. Before long our whole application had seamless Undo/Redo functionality and I was very pleased I’d put the effort in up front to get it right.
doug@jodoro.com[1] We chose to build the front end in Adobe Flex primarily for its rich set of user interface features, and for the ease of distribution to our potential customer base through the Flash plug-in.





